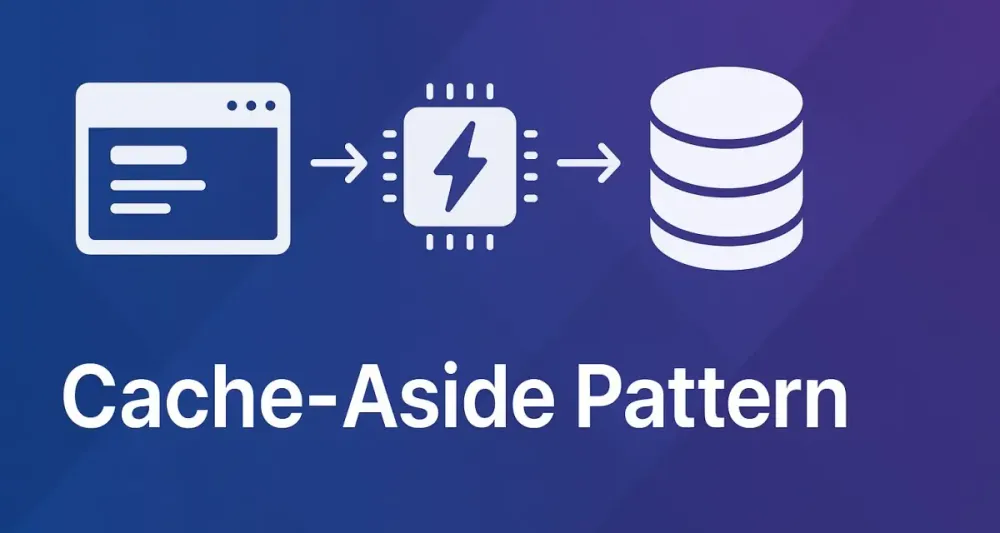
1 Introduction to the Cache-Aside Pattern
Modern applications often face the challenge of delivering data quickly while managing increasing loads. Have you ever clicked a button on a website and felt frustrated waiting several seconds for data to load? Or perhaps noticed your backend services becoming sluggish under heavy traffic? If these scenarios sound familiar, adopting the Cache-Aside pattern might be the solution you’re looking for.
1.1 Definition: Improving Performance by Strategically Caching Data
The Cache-Aside pattern is a caching strategy that boosts application performance by placing frequently accessed data into a fast, temporary storage layer, reducing the need to repeatedly query the slower, persistent data source. Simply put, it means your application checks the cache first before hitting the database, fetching from the database only when necessary.
1.2 Core Concept: Application-Managed Cache Interaction Alongside a System of Record
Unlike some caching mechanisms where the cache and database synchronize automatically, Cache-Aside explicitly delegates caching responsibilities to the application code. The application determines when and how the cache is read, updated, or invalidated.
Imagine the cache as a quick-access notebook and the database as a massive filing cabinet. Instead of constantly rifling through thousands of files for commonly used information, you jot down notes in your notebook for rapid retrieval. Your notebook (cache) isn’t the authoritative source—that’s still your filing cabinet (database)—but it significantly accelerates your work.
1.3 The “Why”: Reducing Latency and Database Load
The primary motivation behind Cache-Aside is performance and scalability. By serving data from the cache whenever possible, latency is dramatically reduced, leading to a smoother, faster experience for users. Additionally, it minimizes load on the database, allowing it to handle more critical operations efficiently.
1.4 Positioning: Its Role as a Fundamental Data Management and Performance Pattern
The Cache-Aside pattern is foundational in the world of software architecture. Although not part of the famous Gang of Four behavioral patterns, it holds a prominent position as a proven solution for enhancing system responsiveness and reducing backend strain.
1.5 Goals: What Cache-Aside Helps Achieve in Cloud and Modern Applications
Key goals include:
- Reduced Latency: Faster responses for end-users.
- Lower Database Load: Decreased pressure on the data source, extending database life and performance.
- Scalability: Improved handling of high-volume traffic without compromising response times.
- Cost Efficiency: Lower resource consumption, potentially reducing operational costs.
2 Core Principles of Cache-Aside Implementation
Implementing Cache-Aside is straightforward when adhering to certain principles:
2.1 Application-Driven Cache Logic
With Cache-Aside, your application explicitly manages cache interactions, following this simple logic:
- Check the cache first.
- If the data isn’t present (a cache miss), fetch from the database.
- Populate the cache with fresh data.
Here’s how that logic looks in C# (.NET 8) using Redis as the cache:
public async Task<Product> GetProductAsync(int productId)
{
string cacheKey = $"product:{productId}";
var cachedProduct = await redisCache.GetStringAsync(cacheKey);
if (cachedProduct != null)
{
return JsonSerializer.Deserialize<Product>(cachedProduct);
}
var product = await dbContext.Products.FindAsync(productId);
if (product != null)
{
await redisCache.SetStringAsync(
cacheKey,
JsonSerializer.Serialize(product),
new DistributedCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromMinutes(10)
});
}
return product;
}2.2 Read Path Optimization
Cache-Aside primarily optimizes read operations. It accelerates data retrieval by significantly reducing database roundtrips, particularly for repetitive read requests.
2.3 Data Source as the Ultimate Truth
While caching improves performance, the database remains your single source of truth. Your cache is an optimized snapshot—not a replacement—of your actual data.
2.4 Cache as Ephemeral Storage
Caches should be considered temporary and volatile. Always expect cache data to potentially vanish due to memory pressure, crashes, or deliberate eviction policies.
3 Key Components and Concepts
Understanding the Cache-Aside pattern requires familiarity with key components:
3.1 Application Code
This is where you manage cache interactions explicitly. The logic should handle cache misses gracefully and repopulate data as needed.
3.2 Cache Store
Typically implemented as in-memory databases such as Redis or Memcached, these stores deliver exceptional speed and responsiveness.
3.3 Data Source (System of Record)
This is your primary persistent store—SQL Server, PostgreSQL, MongoDB, or external APIs. Cache-Aside doesn’t replace this layer but reduces its workload.
3.4 Cache Key
Cache keys uniquely identify cached data. Proper naming conventions avoid collisions and ensure rapid retrieval:
string cacheKey = $"user:profile:{userId}";3.5 Time-To-Live (TTL) / Expiration Policy
Setting a Time-To-Live ensures cache freshness. After expiry, data is evicted automatically, prompting the application to refresh the cache on the next read:
new DistributedCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromMinutes(15)
};4 When to Strategically Employ the Cache-Aside Pattern
4.1 Identifying Read-Heavy Workloads with Repetitive Data Access
If your application frequently retrieves the same data (product catalogs, user profiles, configurations), Cache-Aside is ideal.
4.2 Data with Acceptable Staleness
Consider Cache-Aside when slightly outdated data is acceptable. For example, viewing cached product reviews or inventory counts refreshed every few minutes.
4.3 Appropriate Scenarios
4.3.1 Reducing Latency for Frequently Accessed, Infrequently Changing Data
Use Cache-Aside to speed up data retrieval for items rarely updated but constantly accessed, like configuration settings or reference data.
4.3.2 Decreasing Load on Backend Systems
When databases or external APIs are expensive or rate-limited, caching can substantially decrease load, preserving resources.
4.3.3 Improving Application Scalability and Responsiveness
Scaling becomes easier when caching handles frequent read operations, allowing your backend systems to efficiently manage other crucial tasks.
4.4 Business Cases Driving Adoption
Cache-Aside brings tangible business benefits:
- Enhanced User Experience: Faster page loads and API responses improve satisfaction.
- Cost Reduction: Lower database and API usage reduce infrastructure expenses.
- Meeting SLAs: Ensuring consistently high performance under defined service levels.
4.5 Technical Contexts Where Cache-Aside Shines
Here’s when Cache-Aside typically excels:
4.5.1 Web Applications and APIs Serving User Requests
Rapid user interactions demand minimal latency, perfect for Cache-Aside.
4.5.2 Microservices Accessing Reference or Supporting Data
Microservices frequently use cache to reduce repetitive cross-service calls.
4.5.3 Systems Integrating with Rate-Limited or Slow External Services
Caching minimizes requests, preventing external rate-limit violations and improving reliability.
5 Implementing Cache-Aside in C# and .NET
Architects and senior developers working with .NET and C# often need a robust, scalable, and observable approach to caching. Implementing the Cache-Aside pattern effectively in .NET requires an understanding of both the pattern’s intent and the tools available within the ecosystem. This section explores not just the mechanics, but the design trade-offs, nuanced features, and practical concerns for production systems.
5.1 Core Logic Flow
The cache-aside pattern is based on a straightforward control flow. Yet, a clear mental model is critical, especially as complexity grows with scaling and resilience concerns.
5.1.1 Attempt to Retrieve Data from Cache
Every read starts here. The application checks the cache store using a well-constructed key. This lookup is usually fast, especially with in-memory or distributed caches.
5.1.2 If Cache Hit: Return Data from Cache
If the cache contains the requested data, it’s returned directly. The user benefits from low latency, and the backend database remains untouched.
5.1.3 If Cache Miss
When data is absent, the application proceeds to the authoritative source—the database or external service.
- Retrieve Data from Data Source: Access the primary store, which might be slower.
- Store Data in Cache: After retrieving the data, it’s stored in the cache, often with an appropriate Time-To-Live (TTL) to control freshness.
- Return Data: The data is then returned to the caller.
Let’s outline this in a reusable method signature, which you’ll see echoed in both in-memory and distributed cache implementations:
public async Task<T> GetOrAddAsync<T>(string cacheKey, Func<Task<T>> dataFactory, TimeSpan cacheDuration)This functional approach ensures DRY principles and consistent behavior.
5.2 In-Memory Caching with IMemoryCache
5.2.1 Introduction to Microsoft.Extensions.Caching.Memory
IMemoryCache is Microsoft’s in-memory caching solution for .NET. It’s ideal for single-instance applications or small-scale web apps where each application node maintains its own cache. Configuration and usage are straightforward, leveraging dependency injection for clean separation.
5.2.2 Setting Absolute and Sliding Expiration Policies
Expiration controls how long data stays fresh. There are two primary policies:
- Absolute Expiration: The cache entry expires after a fixed time, regardless of access.
- Sliding Expiration: The expiration clock resets on each access, keeping frequently accessed data alive.
5.2.3 Managing Cache Entry Options (Priority, Size)
Fine-tune caching behavior by assigning priorities or size limits to entries. This is essential when memory is at a premium, and certain data must outlive others.
5.2.4 C# Example: Implementing Cache-Aside with IMemoryCache for a Service Layer
Here’s how you might structure a cache-aside implementation in a service method:
public class ProductService
{
private readonly IMemoryCache _cache;
private readonly MyDbContext _dbContext;
public ProductService(IMemoryCache cache, MyDbContext dbContext)
{
_cache = cache;
_dbContext = dbContext;
}
public async Task<Product> GetProductAsync(int productId)
{
string cacheKey = $"product:{productId}";
if (_cache.TryGetValue(cacheKey, out Product product))
{
return product;
}
product = await _dbContext.Products.FindAsync(productId);
if (product != null)
{
var cacheEntryOptions = new MemoryCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromMinutes(10),
SlidingExpiration = TimeSpan.FromMinutes(5),
Priority = CacheItemPriority.High,
Size = 1
};
_cache.Set(cacheKey, product, cacheEntryOptions);
}
return product;
}
}Notice how options such as priority and size are managed, enabling precise control over eviction behavior.
5.3 Distributed Caching with IDistributedCache
5.3.1 Overview and Use Cases (Scalability, Multi-Instance Deployments)
Distributed caching is essential for applications running across multiple nodes, such as in cloud environments or load-balanced scenarios. It provides a shared cache, allowing data to be consistent and available regardless of which instance handles the request.
5.3.2 Common Providers in .NET
5.3.2.1 Redis (Microsoft.Extensions.Caching.StackExchangeRedis)
Redis is the most common distributed cache for .NET, known for performance, rich data structures, and wide adoption.
5.3.2.2 SQL Server (Microsoft.Extensions.Caching.SqlServer)
For organizations invested in SQL Server, this cache provider stores cached data in SQL tables.
5.3.2.3 Other Options (NCache, Azure Cache for Redis)
Commercial and cloud-hosted options offer advanced features for large-scale needs.
5.3.3 Serialization/Deserialization Considerations (JSON, MessagePack)
Unlike in-memory cache, distributed cache interfaces only store byte arrays. This means objects must be serialized (converted to byte arrays) and deserialized back, introducing complexity.
- JSON: Human-readable, great for debugging, but slower.
- MessagePack: Binary format, smaller and faster.
Choose serialization carefully—data volume and speed matter at scale.
5.3.4 C# Example: Implementing Cache-Aside with IDistributedCache and Redis
Below is a sample implementation using Redis and JSON serialization:
public class DistributedProductService
{
private readonly IDistributedCache _cache;
private readonly MyDbContext _dbContext;
private readonly JsonSerializerOptions _jsonOptions;
public DistributedProductService(IDistributedCache cache, MyDbContext dbContext)
{
_cache = cache;
_dbContext = dbContext;
_jsonOptions = new JsonSerializerOptions { PropertyNamingPolicy = JsonNamingPolicy.CamelCase };
}
public async Task<Product> GetProductAsync(int productId)
{
string cacheKey = $"product:{productId}";
var cachedBytes = await _cache.GetAsync(cacheKey);
if (cachedBytes != null)
{
return JsonSerializer.Deserialize<Product>(cachedBytes, _jsonOptions);
}
var product = await _dbContext.Products.FindAsync(productId);
if (product != null)
{
var cacheOptions = new DistributedCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromMinutes(10)
};
var serialized = JsonSerializer.SerializeToUtf8Bytes(product, _jsonOptions);
await _cache.SetAsync(cacheKey, serialized, cacheOptions);
}
return product;
}
}With distributed cache, attention to serialization, key naming, and expiration is vital.
5.4 Advanced Techniques and .NET Features
Beyond the basics, production-ready caching solutions must tackle asynchronous operations, concurrency, resilience, and maintainability.
5.4.1 Asynchronous Cache Operations: Using async/await for Non-Blocking Cache Access
Most cache providers, including Redis and distributed cache abstractions, support asynchronous operations. Leveraging async/await prevents thread starvation and scales better in web applications.
5.4.1.1 C# Example: GetOrCreateAsync Pattern
You can generalize cache-aside logic with a reusable pattern, similar to what you’d see in modern .NET libraries:
public static class CacheExtensions
{
public static async Task<T> GetOrCreateAsync<T>(
this IDistributedCache cache,
string cacheKey,
Func<Task<T>> factory,
TimeSpan ttl,
JsonSerializerOptions options = null)
{
var cached = await cache.GetAsync(cacheKey);
if (cached != null)
{
return JsonSerializer.Deserialize<T>(cached, options ?? new JsonSerializerOptions());
}
var data = await factory();
if (data != null)
{
var serialized = JsonSerializer.SerializeToUtf8Bytes(data, options ?? new JsonSerializerOptions());
await cache.SetAsync(cacheKey, serialized, new DistributedCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = ttl
});
}
return data;
}
}This extension method encourages reusability and clarity in business logic.
5.4.2 Handling Concurrent Cache Misses (Cache Stampede/Dogpiling)
5.4.2.1 Explanation of the Problem
A cache stampede occurs when many concurrent requests trigger a cache miss for the same key. Each then queries the backend, potentially overwhelming the system.
5.4.2.2 Techniques like Lazy<Task> or SemaphoreSlim for Request Coalescing
To mitigate, synchronize access to the data factory, ensuring only one request loads data and populates the cache, while others await the result.
5.4.2.3 C# Example: Mitigating Cache Stampede
private static readonly ConcurrentDictionary<string, SemaphoreSlim> _locks = new();
public async Task<T> GetOrAddAsync<T>(
string cacheKey,
Func<Task<T>> factory,
TimeSpan ttl)
{
var cached = await _cache.GetAsync(cacheKey);
if (cached != null)
{
return JsonSerializer.Deserialize<T>(cached);
}
var myLock = _locks.GetOrAdd(cacheKey, _ => new SemaphoreSlim(1, 1));
await myLock.WaitAsync();
try
{
cached = await _cache.GetAsync(cacheKey);
if (cached != null)
return JsonSerializer.Deserialize<T>(cached);
var data = await factory();
if (data != null)
{
var serialized = JsonSerializer.SerializeToUtf8Bytes(data);
await _cache.SetAsync(cacheKey, serialized, new DistributedCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = ttl
});
}
return data;
}
finally
{
myLock.Release();
_locks.TryRemove(cacheKey, out _);
}
}This strategy efficiently handles high-concurrency scenarios and protects the backend.
5.4.3 Polly for Resilient Cache Interactions
5.4.3.1 Using Polly Policies (e.g., Fallback, Timeout) Around Cache Access
Polly is a popular .NET resilience and transient-fault-handling library. You can wrap cache calls with retry, timeout, or fallback policies, improving stability, especially if the distributed cache is remote or under load.
5.4.3.2 Caching Results of Resilient Operations
You may want to cache not only successful results but also the outcome of expensive, fault-tolerant operations, so users aren’t waiting for repeated retries.
Here’s a simplified example:
var policy = Policy
.Handle<Exception>()
.WaitAndRetryAsync(3, _ => TimeSpan.FromMilliseconds(100));
var product = await policy.ExecuteAsync(() => GetProductAsync(productId));Use policies judiciously, balancing resilience with the risk of masking systemic issues.
5.4.4 Strongly-Typed Cache Keys and Cache Key Generation Strategies
Cache keys should be unambiguous, stable, and collision-resistant. Prefer strongly-typed methods or cache key builders to avoid accidental overlap.
public static string GetProductCacheKey(int productId) => $"product:{productId}";Complex keys (involving tenant IDs, regions, etc.) can use hash functions or serialization of parameter objects.
5.5 Cache Invalidation Strategies – The Achilles’ Heel
Cache invalidation is widely regarded as one of the hardest problems in distributed systems. If cache entries aren’t invalidated correctly, stale or incorrect data can be served to users, undermining trust and reliability.
5.5.1 Time-To-Live (TTL): Most Common, but Leads to Potential Staleness
TTL-based eviction is simple and ensures periodic refresh. However, this means users might see stale data until the TTL expires, especially in rapidly changing environments.
5.5.2 Explicit Invalidation on Data Change
5.5.2.1 Application-Triggered (e.g., After an Update Operation)
Whenever data is changed in the system of record, the cache entry is immediately removed or updated. This reduces staleness but increases implementation complexity.
For example:
public async Task UpdateProductAsync(Product product)
{
_dbContext.Products.Update(product);
await _dbContext.SaveChangesAsync();
await _cache.RemoveAsync($"product:{product.Id}");
}5.5.2.2 Challenges in Distributed Systems
In distributed architectures, propagating invalidation to all nodes and caches reliably is non-trivial. Race conditions, network partitions, and eventual consistency all add complexity.
5.5.3 Event-Driven Invalidation: Using a Message Bus
To propagate invalidation efficiently, publish data-change events on a message bus (such as Azure Service Bus or RabbitMQ). All subscribing application instances receive the notification and invalidate relevant cache entries.
Example flow:
- Product is updated in the database.
- Application publishes a
ProductUpdatedevent to the bus. - All service nodes receive the event and remove the corresponding cache entry.
This pattern is especially effective in microservice or horizontally scaled environments.
5.5.4 Write-Through/Write-Around Considerations
Write-Through: All data updates go through the cache, which then persists changes to the database. The cache always has fresh data, but write operations become more complex.
Write-Around: Data is written directly to the database, bypassing the cache. The cache entry is explicitly removed or allowed to expire naturally.
Cache-Aside differs by making the application fully responsible for cache reads and invalidations—writes are not routed through the cache by default.
5.6 Observability: Monitoring Cache Effectiveness in .NET
Effective cache use isn’t just about implementation—it’s about measurement and understanding impact. Observability enables you to answer critical questions about performance and correctness.
5.6.1 Key Metrics
- Hit Rate: Ratio of cache hits to total requests. High values indicate efficient caching.
- Miss Rate: Percentage of requests falling through to the data source.
- Cache Latency (Get/Set): Time taken to retrieve or update cache entries.
- Cache Size: Total number of items or memory consumed.
- Eviction Count: How often entries are removed (by expiration or memory pressure).
These metrics provide insight into cache health and guide tuning efforts.
5.6.2 Using System.Diagnostics.Metrics or APM Tools
Modern .NET supports metrics via System.Diagnostics.Metrics, and integrates with Application Performance Monitoring (APM) tools like Application Insights, OpenTelemetry, Datadog, and New Relic.
Example of custom metrics setup:
using System.Diagnostics.Metrics;
public static class CacheMetrics
{
private static readonly Meter _meter = new("MyApp.Cache");
public static readonly Counter<long> CacheHits = _meter.CreateCounter<long>("cache_hits");
public static readonly Counter<long> CacheMisses = _meter.CreateCounter<long>("cache_misses");
}Instrument cache operations to emit events, then visualize and analyze trends with your monitoring platform.
5.6.3 Logging Cache Events
Beyond metrics, detailed logs help troubleshoot specific cache behaviors:
- Misses: Identify which data is causing backend load.
- Errors: Spot connectivity issues or serialization problems.
- Evictions: Understand why and when data is removed.
Integrate logs with your observability pipeline, correlating cache events with overall system performance.
6 Real-World Use Cases and Architectural Scenarios
The cache-aside pattern is not just theoretical. It’s shaped by the practical needs of large-scale, modern software systems—especially in distributed and cloud environments. Let’s look at how leading architectures employ this pattern to solve real business problems.
6.1 Caching Product Details and Lists in an E-commerce Platform
In e-commerce, product catalogues, item details, and category listings are accessed at a high frequency. Most users browse before making a purchase, generating immense read traffic on data that changes only occasionally (for example, when inventory is updated or a product is edited).
A cache-aside approach allows you to store product information in a cache, reducing both database load and end-user latency. When a customer views a product page, the application first checks the cache for details. If present, the cache serves the information in milliseconds. On a miss, the system fetches from the primary database and updates the cache. Price changes, new reviews, or inventory adjustments can be used to invalidate specific cache entries, ensuring users see timely and accurate information.
Architectural Tip: When product data is updated by a back-office admin, publish an event to a message bus (e.g., “ProductUpdated”) so all app instances can invalidate the relevant cache entry, keeping distributed caches in sync.
6.2 Storing User Session Information or Frequently Accessed Profile Data
Session data and user profiles are classic caching candidates. Retrieving session state or profile details from a relational store on every HTTP request is inefficient and costly, especially as user bases grow.
With cache-aside, user data can be stored in memory or a distributed cache. On login or session creation, profile information is loaded and cached. For the lifetime of the session or until an explicit profile change occurs, repeated requests can quickly fetch details from the cache. If profile information is edited, the cache entry is invalidated immediately so subsequent requests see the updated data.
Security Note: Be diligent about securing sensitive session data in the cache. Use encrypted connections and, if necessary, encrypt cache payloads.
6.3 Caching Reference Data
Reference data such as country lists, product categories, tax rates, or configuration settings is often read-heavy and write-rare. The cost of a cache miss is low compared to the benefit of rapid reads. Storing these lists in cache avoids unnecessary hits on a configuration database, reducing latency for every API or page load that requires them.
Because this data is rarely changed, longer TTLs or even manual invalidation on update is reasonable. In many organizations, these lists change only through administrative dashboards, making invalidation straightforward to implement.
6.4 Reducing Latency for Data Aggregated from Multiple Microservices
In microservice architectures, assembling a composite response often means calling multiple services—each adding latency and potential failure points. By caching aggregate or “view model” results at the gateway or API layer, the application can quickly respond to repeated requests without making redundant calls downstream.
For example, a “user dashboard” view that combines account status, recent orders, and loyalty points might fetch and cache the entire response. If any underlying data changes, appropriate events can trigger invalidation of the composite cache entry.
6.5 Offloading Reads from a Relational Database to Improve Write Performance
High read loads can limit write throughput on relational databases, especially in scenarios like reporting, analytics, or popular content feeds. By caching the results of common queries or reports, you reduce the read load, freeing up the database to process inserts and updates more efficiently.
In some architectures, “read replicas” are paired with caching to further improve scale and reliability. Cache-aside ensures that transient spikes in demand don’t overwhelm the backend and provides a buffer for gracefully absorbing traffic surges.
7 Common Anti-Patterns and Pitfalls to Avoid
While cache-aside is powerful, misuse or oversight can undermine its effectiveness. Awareness of these pitfalls helps avoid hard-to-diagnose production problems.
7.1 Caching Stale Data Indefinitely
Failing to set an appropriate TTL or neglecting explicit invalidation can lead to serving stale, incorrect data. This is especially problematic for data that changes often or has compliance requirements for freshness.
7.2 Overly Aggressive Caching of Volatile Data
Caching data that changes frequently (such as stock prices or user order status) can result in inconsistent views and a poor user experience. For such data, consider caching at a lower layer, reducing TTL, or bypassing the cache for specific reads.
7.3 Ignoring Cache Miss Storms (Cache Stampede/Dogpiling)
When a popular cache entry expires or is invalidated, many concurrent requests may simultaneously trigger slow database queries, overwhelming the backend. Mitigation techniques include request coalescing (using locks or Lazy<Task<T>>), staggered expiration, or pre-warming cache entries.
7.4 Inefficient/Poor Cache Key Design
Using broad or ambiguous keys (such as “product”) leads to overwriting unrelated data or cache collisions. Conversely, using overly granular keys (with unnecessary parameters) bloats the cache and lowers hit rates. Design keys carefully, using a consistent, explicit pattern.
7.5 Not Handling Cache Store Unavailability Gracefully
Treat the cache as a performance optimization, not a required dependency. If the cache is unavailable, the application should degrade gracefully and fetch data from the source, perhaps with rate limiting or circuit breaking to protect the backend.
7.6 Caching Large, Infrequently Used Objects
Storing big, rarely accessed objects in cache wastes memory and can force out more useful, hot data. Always profile usage patterns and consider maximum cache entry sizes.
7.7 Forgetting Security Implications
Caching sensitive data (PII, tokens, payment details) without access controls or encryption can lead to data leaks. Always restrict cache access and encrypt sensitive values, especially in distributed caches that may be accessible from multiple networks.
7.8 Treating Cache as a System of Record
Never rely on the cache as your only data source. If the cache fails or is cleared, the data is lost. Your system of record (database or external service) must always be the authoritative source.
7.9 Inconsistent Serialization/Deserialization
Switching serialization libraries or changing data contracts without backward compatibility can break cache retrieval, especially in distributed scenarios. Standardize serialization strategies and maintain versioning discipline for cache payloads.
8 Advantages and Benefits of the Cache-Aside Pattern
Despite the caveats, cache-aside remains a foundational pattern for many architectures. Here’s why it’s widely adopted.
8.1 Improved Application Performance and Responsiveness
By serving data from fast memory stores, you can cut response times from hundreds of milliseconds to single-digit milliseconds, dramatically improving user experience.
8.2 Reduced Load on Backend Data Stores and External Services
Caching offloads repetitive reads, decreasing load and latency on databases or APIs. This enables those services to focus on writes or complex queries.
8.3 Increased Application Scalability
Efficient caching means your application can support higher request volumes without a corresponding increase in database resources.
8.4 Potential Cost Savings
Fewer database transactions and reduced usage of third-party APIs mean lower infrastructure and licensing costs. Memory is typically cheaper to scale than relational database capacity.
8.5 Relative Simplicity of Implementation for the Read Path
Cache-aside is simple to understand and integrate into existing business logic, requiring no changes to the underlying data store.
8.6 Flexibility in Choosing Cache Stores
You’re free to use different cache stores (in-memory for single instance, Redis for distributed, or cloud-managed caches), and switch providers as requirements evolve.
9 Disadvantages and Limitations to Consider
No pattern is a panacea. Cache-aside has several limitations that must be considered in design and operations.
9.1 Data Staleness
Because cache-aside relies on TTLs and explicit invalidation, it’s possible for users to receive outdated information—sometimes for several minutes. For use cases requiring strict consistency, alternative approaches or additional mechanisms are necessary.
9.2 Increased Code Complexity
Application logic must now manage cache interactions, invalidation, and error handling. This adds code paths, testing requirements, and operational risk.
9.3 Cache Miss Penalty
The first request for uncached data (a “cold cache” or after eviction) incurs the full cost of a backend query and cache population. Under high concurrency, this can impact perceived performance.
9.4 Additional Infrastructure
Introducing a cache means managing another piece of infrastructure—provisioning, scaling, monitoring, and securing it appropriately. For global applications, regional cache replication or geo-distribution further increases operational complexity.
9.5 Cache Invalidation Complexity
Invalidation logic, especially in distributed or microservices environments, is often cited as the hardest part of caching. Race conditions, out-of-order event delivery, or partial failures can result in serving stale or inconsistent data.
9.6 Cache Store as a Potential Bottleneck or Point of Failure
If the cache cluster becomes unavailable or overloaded, application performance may degrade, or in worst cases, the application may fail entirely if not designed to fall back on the system of record. High-availability and resilience strategies are critical.
10 Conclusion and Best Practices for .NET Architects
The cache-aside pattern remains an indispensable tool for architects designing scalable, responsive, and cost-efficient systems with .NET. Its flexibility and effectiveness are balanced by the need for careful engineering and operational diligence.
10.1 Recap: Cache-Aside as an Essential Tool in a .NET Architect’s Performance Toolkit
Cache-aside is proven, practical, and well-supported in .NET through libraries such as IMemoryCache and IDistributedCache. It works for a wide variety of scenarios, from single-node web apps to distributed microservices.
10.2 Strategic Selection
Not all data benefits equally from caching. Focus on read-heavy, rarely-changing, or computationally expensive data for best results. Avoid caching volatile, high-churn, or sensitive data without due diligence.
10.3 Prioritize Robust Invalidation and Coherency
Effective invalidation is often the most challenging aspect. Invest in clear cache key strategies, event-driven invalidation mechanisms, and thorough testing of cache consistency under concurrent updates.
10.4 Design for Failure
Expect the cache to be temporarily unavailable. Build fallback logic so your application continues to function, even if only at degraded performance.
10.5 Monitor, Measure, and Tune
Instrument your cache with metrics and logging. Regularly review hit/miss rates, latency, and cache size to adjust TTLs, eviction policies, and cache entry selection.
10.6 Choose the Right Cache Technology
Use IMemoryCache for single-instance or development environments. For horizontally-scaled or cloud-native apps, prefer IDistributedCache backed by Redis, SQL Server, or managed cache solutions. Evaluate trade-offs between cost, performance, and operational burden.
10.7 Combine with Other Patterns
Caching often works best when combined with other resilience and scaling patterns. Consider circuit breakers to prevent cascading failures, bulkheads to isolate workloads, and asynchronous refresh (cache warming) to mitigate cold cache penalties.