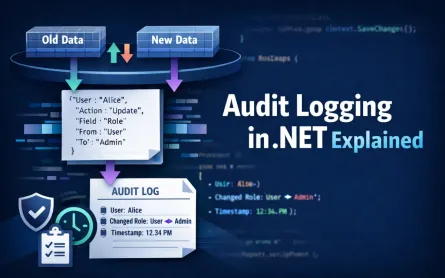
1 The Case for Sharding: Limits of Vertical Scaling and Strategic Decisions
Sharding becomes relevant when a single database can no longer keep up with real-world workload demands. At some point, adding more CPU, RAM, or storage stops helping, and the database turns into the bottleneck for the entire system. This section explains how to recognize those limits, what sharding actually changes, and what trade-offs follow when data is spread across multiple servers. The goal is to give you a practical understanding of when sharding is the right move and what it costs operationally.
1.1 The Tipping Point: Recognizing When Vertical Scaling (Scale-Up) and Read Replicas Are No Longer Sufficient
Most systems grow by scaling up a single database server. This works for a long time, and cloud platforms make these upgrades painless. But every engine eventually reaches a point where more hardware no longer solves the problem.
A common early warning sign is write saturation. Read replicas help with read-heavy workloads, but all writes must still go to the primary. When write throughput consistently pushes past what a single node can handle, the system has outgrown vertical scaling. Another sign is memory pressure. Once the active dataset no longer fits in RAM, even well-indexed queries start hitting disk more often, causing unpredictable latencies. Maintenance operations—index rebuilds, VACUUM, checkpoints—also take longer as data grows, making routine upkeep risky and disruptive.
Hotspotting is another indicator. When traffic concentrates heavily on a particular tenant or entity (such as one customer or a specific user group), the system becomes unbalanced. One logical partition of the data ends up dictating the performance of the entire database. This is common in SaaS environments where large tenants can overwhelm smaller ones on the same server.
Finally, availability becomes a concern. A vertically scaled primary is a single point of failure. Even with replicas, the architecture still depends on the primary’s capacity. When uptime or recovery requirements exceed what a single node can reliably deliver, it’s a sign that the architecture needs to evolve.
When these signals appear together—write pressure, latency instability, tenant imbalance, and long maintenance cycles—it’s usually time to distribute data horizontally. Sharding is often the cleanest way to do that.
1.2 Sharding vs. Partitioning: Clarifying the Difference Between Table Partitioning (Local) and Horizontal Sharding (Distributed)
Partitioning and sharding often get mixed up because both split data. But they solve different problems and operate at different levels.
Partitioning divides tables inside a single database instance. Whether it’s SQL Server’s table partitioning, PostgreSQL’s declarative partitions, or MongoDB’s internal chunking on a single node, everything still lives on one machine. Partitioning helps with query pruning, archival, and maintenance—your optimizer can skip irrelevant partitions—but all reads and writes still compete for the same CPU, memory, and storage.
Sharding distributes data across multiple independent database servers. Each shard has its own resources and can operate autonomously. Failures affect only a subset of data. Scaling becomes a matter of adding more shards, not buying a bigger machine. But sharding also requires external routing logic: the application (or a sharding middleware) must know where each piece of data lives.
One simple way to distinguish the two:
If losing one database instance takes out the entire dataset, you partitioned. If losing one instance only affects part of the dataset, you sharded.
This difference matters because it defines your failure mode, your scaling limits, and the complexity of your application code.
1.3 The Trade-Off Matrix: Analyzing the Operational Complexity Cost vs. Performance Benefits
Sharding delivers horizontal scale and isolation, but it adds operational overhead. The decision is rarely straightforward. You gain performance and resilience, but you also take on distributed system behaviors that didn’t exist before.
1.3.1 CAP Theorem Implications in a Sharded Environment
Once data spans multiple nodes, the system must handle network partitions. That immediately puts you into the realm of the CAP theorem. A single database doesn’t need to make CAP choices because all operations are local. Sharding forces you to decide what the system should prioritize during failures.
In real deployments:
- Application-sharded SQL Server and PostgreSQL setups often lean toward Availability + Partition Tolerance because operations continue even if some shards become unreachable. Consistency is enforced at the business logic layer.
- MongoDB allows adjustable consistency levels but tends to behave like a CP system during failovers, where writes may briefly block until a majority of replicas agree.
- Citus for PostgreSQL acts more like CP, since the coordinator node controls distributed queries and consistency across worker nodes.
In a .NET application, these choices are not just database concerns—they shape your routing logic, retry behavior, and error handling. You end up defining consistency in application code rather than relying purely on the database.
1.3.2 Impact on ACID Compliance and Development Velocity
ACID transactions work reliably within a single shard, but not across multiple shards without extra coordination. Once data is distributed, you lose the convenience of multi-table joins and transactions that span the whole dataset. Cross-shard writes require patterns like 2PC (rarely recommended), sagas, or compensating actions.
This changes how teams work:
- Queries that used to rely on joins now must fetch data from multiple sources or use pre-joined read models.
- Writes often become asynchronous to avoid blocking when coordinating multiple shards.
- Background processors—outbox consumers, saga orchestrators, message brokers—become essential for maintaining correctness.
These changes add overhead and slow down initial development. Teams need time to adjust to the boundaries and routing rules. But the payoff is significant: the system can scale far beyond the limitations of a single database, and performance becomes more predictable as load grows.
2 Core Sharding Topologies and Routing Algorithms
Once you decide that sharding is necessary, the next question is how to distribute data and how the application will know where each record lives. The choice of shard key and routing strategy shapes the system for years, so it needs to be made with care. This section walks through the core sharding topologies used in .NET applications and explains when each one fits.
2.1 Key Based Sharding (Hash Based)
Hash-based sharding is one of the most common approaches. It takes a key—often a tenant ID, user ID, or order ID—runs it through a hash function, and uses the output to pick the shard. It works well when you want an even distribution of data without maintaining much metadata.
2.1.1 Standard Hashing vs. Consistent Hashing (Ring)
A straightforward approach uses a modulo operation:
shardId = hash(key) % shardCount;This distributes keys evenly as long as the number of shards never changes. But as soon as you add or remove a shard, nearly every key ends up mapping to a different shard. That means a full data reshuffle—something you want to avoid in production. This is why most teams using simple hashing eventually hit a wall.
Consistent hashing solves this problem by organizing shards on a logical “ring.” Instead of recalculating everything, only the hash ranges next to a new or removed shard shift. Most keys remain where they are. Systems like Redis Cluster and Cassandra lean heavily on this idea, and it works just as well when applied to database sharding.
In a .NET application, consistent hashing usually lives inside a routing service. A typical implementation uses a sorted dictionary or balanced tree so the application can quickly determine which shard owns a particular portion of the ring.
2.1.2 Using Virtual Nodes to Prevent Hotspots During Scaling
Even with consistent hashing, one shard might still end up with more load simply because the hash distribution is uneven. Virtual nodes (“vnodes”) fix this. Instead of placing each physical shard once on the ring, you place it many times—50, 100, or more. Each vnode holds a small slice of the hash space.
This has two benefits:
- Load spreads more evenly because each shard controls many small ranges.
- When rebalancing, the system moves small virtual buckets instead of huge data chunks.
Teams dealing with uneven tenant sizes—common in SaaS, gaming, or IoT ingest—see major stability improvements with virtual nodes. The system can gradually shift buckets as tenants grow without taking big risks.
2.2 Range Based Sharding
Range sharding places data into shards based on ordered ranges rather than hashes. It’s a good fit for workloads where data naturally follows a timeline or sorted sequence, such as time-series logs or financial records.
2.2.1 Handling Sequential Data and the “Heat” Problem at the End of the Range
Range sharding’s main challenge is that new data almost always lands in the last range. That “end shard” becomes the write hotspot. Performance degrades as the shard absorbs more than its share of inserts.
Teams usually handle this problem using one or more techniques:
- Creating empty future shards ahead of time to spread load earlier
- Using a hybrid “range + hash” model so writes spread across multiple shards
- Splitting the hottest shard automatically once it hits certain thresholds
Many large systems keep the newest data on fast storage while pushing older data to cheaper nodes. In .NET, the router simply inspects the timestamp or sequential key and directs it to the right shard.
2.3 Directory/Lookup Based Sharding: Creating a Flexible Map-Based Routing Service
Directory-based sharding replaces math with a central lookup table. Instead of hashing or checking ranges, the application queries a mapping of key → shard. This offers full flexibility—any key can be moved to any shard whenever needed.
These directories often live in:
- Redis
- A dedicated “shard map” SQL table
- A centralized configuration or metadata service
The primary advantage is control. If one tenant grows too quickly, you can move them to another shard without redesigning the algorithm. The trade-off is operational overhead: the lookup must be fast, consistent, and highly available. Most .NET systems cache directory entries aggressively so that routing doesn’t become a bottleneck.
Directory-based sharding works well for SaaS platforms where tenants differ in size and activity level. It gives operators the ability to rebalance individual tenants instead of reshuffling entire hash ranges.
2.4 Geo-Partitioning: Compliance (GDPR) and Latency Reduction Strategies
Some architectures shard by geography rather than load. Each region has its own shard or shard set, and data for users in that region stays local. This helps with regulatory requirements like GDPR and reduces latency by keeping reads and writes close to the user.
The routing logic in .NET usually derives the region from:
- User or tenant configuration
- Authentication claims
- IP geolocation
- A regional endpoint the user is tied to
Once the region is known, routing becomes straightforward: the connection factory picks the database belonging to that region.
Cross-region writes are still challenging. Teams often use asynchronous replication or event-driven workflows because synchronous replication across continents introduces unacceptable latency.
2.5 Multi-Tenant Strategies: Shared Database vs. Schema-per-Tenant vs. Database-per-Tenant
Many .NET systems use sharding to support multi-tenant environments. The right strategy depends on tenant isolation, operational overhead, and scaling requirements.
Shared Database All tenants share the same schema, and tenant_id scopes visibility. This is efficient and easy to manage, but isolation is weak.
Schema-per-Tenant Each tenant gets its own schema. This improves isolation and makes per-tenant backup/restore easier, but managing thousands of schemas requires automation.
Database-per-Tenant Each tenant gets a dedicated database or shard. This offers the strongest isolation but demands the most operational tooling and monitoring.
A well-designed .NET sharding layer abstracts these models so application code doesn’t have to care whether a tenant lives in a shared schema or a dedicated database. Large tenants might even require multiple shards, and the routing logic must support that without complicating business code.
3 Architecting the .NET Sharding Layer (Application-Side Routing)
A sharded system works only if most developers never think about shards at all. The routing rules, shard selection, and connection logic must stay hidden behind clean abstractions. The .NET ecosystem gives you the tools to do that—middleware, dependency injection, interceptors, and flexible database providers. With the right structure, business logic remains unchanged while the routing layer quietly decides which database to talk to.
3.1 The Sharding Middleware Pattern
In an application-side routing approach, the application—not the database—chooses which shard to use. This gives you full control and works consistently across SQL Server, PostgreSQL, and MongoDB. The pattern usually consists of four moving parts:
- A shard resolver (hash-based, range-based, or directory lookup)
- A connection factory that builds connections for the selected shard
- A request-scoped context storing the shard key
- EF Core or ADO.NET integration that consumes this routing information
The goal is simple: let application code ask for a DbContext or DbConnection without worrying about where the data actually lives.
3.1.1 Implementing IDbConnectionFactory with Routing Logic
A custom connection factory is the core of the routing layer. It abstracts shard selection so that services can open a database connection just like they would in a non-sharded system.
public interface IShardedConnectionFactory
{
DbConnection CreateConnection(string logicalKey);
}
public class ShardedConnectionFactory : IShardedConnectionFactory
{
private readonly IShardResolver _resolver;
private readonly IDictionary<string, string> _connectionStrings;
public ShardedConnectionFactory(IShardResolver resolver,
IDictionary<string,string> connStrings)
{
_resolver = resolver;
_connectionStrings = connStrings;
}
public DbConnection CreateConnection(string logicalKey)
{
var shardId = _resolver.ResolveShard(logicalKey);
var connString = _connectionStrings[shardId];
return new SqlConnection(connString);
}
}The resolver handles all the logic—hashing, range evaluation, directory lookup—while the factory simply converts that decision into a connection. From the caller’s perspective, nothing changes: they just ask for a connection using a logical identifier like tenantId or userId.
3.1.2 Dependency Injection (DI) Strategies for Dynamic Context Resolution
Shard selection is almost always tied to the request. That might be a tenant ID from a JWT claim, a key in a header, or a region identifier. The DI container should provide a scoped service that holds this information so it is automatically available to anything that needs it.
A small scoped context is enough:
public interface IRequestShardContext
{
string Key { get; }
}
public class RequestShardContext : IRequestShardContext
{
public string Key { get; set; }
}Middleware can populate this value early in the request:
public async Task InvokeAsync(HttpContext context, RequestShardContext shardCtx)
{
shardCtx.Key = context.User.FindFirst("tenant_id")?.Value;
await _next(context);
}Once the context is set, any service that uses the connection factory automatically opens connections to the correct shard. This keeps routing concerns out of controllers, repositories, and business logic.
3.2 EF Core Integration
EF Core can work seamlessly in a sharded architecture as long as the routing layer updates the connection string before EF opens the underlying connection. Two features make this possible: interceptors and global query filters.
3.2.1 Using DbContext Interceptors for Dynamic Connection Switching
Connection interceptors let you modify the connection string right before EF Core opens it. This gives you a reliable hook to inject the correct shard connection dynamically.
public class ShardConnectionInterceptor : DbConnectionInterceptor
{
private readonly IRequestShardContext _shardContext;
private readonly IShardedConnectionFactory _factory;
public ShardConnectionInterceptor(IRequestShardContext context,
IShardedConnectionFactory factory)
{
_shardContext = context;
_factory = factory;
}
public override InterceptionResult ConnectionOpening(
DbConnection connection,
ConnectionEventData eventData,
InterceptionResult result)
{
var newConn = _factory.CreateConnection(_shardContext.Key);
connection.ConnectionString = newConn.ConnectionString;
return result;
}
}With this setup, you can inject a single DbContext type into any service. EF Core automatically connects to the correct shard based on the tenant’s context. No DbContext subclass explosion, no custom factories per shard—just one interceptor that handles routing globally.
3.2.2 Global Query Filters for Multi-Tenancy Within Shards
Even inside a shard, you might host multiple tenants. EF Core’s global query filters help enforce tenant isolation by embedding a filter condition into every query.
protected override void OnModelCreating(ModelBuilder builder)
{
builder.Entity<Order>()
.HasQueryFilter(o => o.TenantId == _tenantContext.Id);
}This works regardless of the sharding model (shared-database, schema-per-tenant, or database-per-tenant). It ensures developers can’t accidentally read or update data belonging to the wrong tenant. The routing layer handles which shard to connect to; global filters handle what data is visible once you’re there.
3.3 Open-Source Libraries & Tools
Some teams build the routing layer themselves. Others prefer using well-tested libraries that handle routing and sharding conventions for them.
3.3.1 Evaluating ShardingCore (Popular .NET Sharding Framework)
ShardingCore is a widely used .NET library that provides built-in support for horizontal sharding on top of EF Core. It offers:
- Automatic routing based on attributes or configuration rules
- Support for horizontal tables and database sharding
- Built-in tenant patterns
- Shard-aware migrations
Its strengths are ease of adoption and reduced boilerplate. Teams with straightforward sharding needs often benefit from using it instead of maintaining their own infrastructure. The trade-off is flexibility—custom routing schemes and nonstandard topologies may not fit ShardingCore’s model as well as hand-written logic.
3.3.2 Using Polly for Resilience and Retries Across Distributed Nodes
Sharded systems introduce more network boundaries and more chances for failures. Instead of scattering try/catch blocks everywhere, it’s better to wrap database operations with resilience policies. Polly makes this easy.
var policy = Policy
.Handle<SqlException>()
.WaitAndRetryAsync(new[]
{
TimeSpan.FromMilliseconds(100),
TimeSpan.FromMilliseconds(300),
TimeSpan.FromMilliseconds(800)
});
await policy.ExecuteAsync(() => command.ExecuteNonQueryAsync());You can apply these policies in the connection factory, repository layer, or EF Core interceptors. This drastically improves reliability, especially during shard rebalancing or when certain shards experience transient load spikes.
4 Managing Distributed Data Integrity and Identity
Once a system moves from a single database to multiple shards, several assumptions stop working. Identity generation, transactions, and consistency rules that were simple in a monolith now need explicit design. A sharded system doesn’t give you global uniqueness “for free,” and transactions no longer span the whole dataset. This section explains how to keep data consistent across shards and how to design identity and transaction patterns that fit naturally into a distributed .NET architecture.
4.1 Global Identity Generation
Sharding changes how you generate primary keys. A good global ID must be unique across all shards, fast to generate, and predictable enough for indexing. Because IDs often influence routing, ordering, and storage layout, choosing the right strategy early saves major operational pain later.
4.1.1 The Problem with IDENTITY(1,1) and AUTO_INCREMENT
Identity columns tied to a single database node don’t work well in a sharded system. Each shard can auto-increment locally, but the moment you need to merge or move data, you face collisions—two shards will inevitably generate the same values. Even tricks like using odd numbers for one shard and even numbers for another fall apart when the shard count changes or when tenants need to be rebalanced.
There’s another issue: sequential IDs create hotspots. Inserts always occur at the end of the index, which pushes write pressure to a small part of the storage layout. In a single database this is manageable, but in a sharded environment it magnifies the imbalance. Any large migration or shard split requires rekeying millions of rows, which is slow and risky.
For real-world distributed systems, database-driven identity auto-increment is simply not sustainable. The identity generation must move outside the database.
4.1.2 Implementing Twitter Snowflake Algorithm in C#
The Twitter Snowflake algorithm is one of the most popular ways to generate globally unique IDs in sharded systems. It creates 64-bit IDs that combine a timestamp with worker and datacenter identifiers. Because the timestamp is the highest-order part of the number, the IDs appear in roughly sorted order, which helps with index locality.
In a .NET sharded environment, the worker and datacenter IDs often map directly to shards or regions. That makes it easy to track where data originated without extra metadata tables.
public class SnowflakeIdGenerator
{
private static readonly object _sync = new();
private const long Twepoch = 1288834974657L;
private const int WorkerIdBits = 5;
private const int DatacenterIdBits = 5;
private const int SequenceBits = 12;
private readonly long _workerId;
private readonly long _datacenterId;
private long _lastTimestamp = -1L;
private long _sequence = 0L;
public SnowflakeIdGenerator(long workerId, long datacenterId)
{
_workerId = workerId;
_datacenterId = datacenterId;
}
public long NextId()
{
lock (_sync)
{
var timestamp = CurrentTime();
if (timestamp < _lastTimestamp)
throw new Exception("Clock moved backwards");
if (timestamp == _lastTimestamp)
{
_sequence = (_sequence + 1) & ((1 << SequenceBits) - 1);
if (_sequence == 0)
timestamp = WaitNextMillis(timestamp);
}
else
{
_sequence = 0;
}
_lastTimestamp = timestamp;
return ((timestamp - Twepoch) << (WorkerIdBits + DatacenterIdBits + SequenceBits))
| (_datacenterId << (WorkerIdBits + SequenceBits))
| (_workerId << SequenceBits)
| _sequence;
}
}
private static long CurrentTime() => DateTimeOffset.UtcNow.ToUnixTimeMilliseconds();
private long WaitNextMillis(long lastTimestamp)
{
var ts = CurrentTime();
while (ts <= lastTimestamp)
ts = CurrentTime();
return ts;
}
}Registering this generator as a singleton in DI lets every service generate IDs without round-tripping to a database or a shared service. The IDs remain globally unique and maintain enough ordering to keep indexes efficient.
4.1.3 UUID v7 (Time-Sorted) vs. Hi/Lo Algorithms
UUID v7 is a more recent specification designed specifically for distributed systems. It embeds the timestamp directly into the UUID, which avoids the random-write penalty of older UUID versions. The main benefit is simplicity: most .NET libraries already support it, and there’s no coordination needed across shards.
The Hi/Lo algorithm offers another alternative. It asks a central source for a batch of high values (“Hi”) and then generates the lower portion (“Lo”) locally. It cuts down on contention, but the system still relies on a central authority for issuing Hi values. If that service is slow or unavailable, ID generation stalls.
In practice:
- UUID v7 is easiest to integrate and works well for many .NET applications.
- Snowflake is the most predictable and operationally robust for high-throughput scenarios.
- Hi/Lo works, but introduces an extra dependency that must be highly available.
For systems planning to scale aggressively, Snowflake or UUID v7 tend to be safer long-term choices.
4.2 Distributed Transactions
With a single database, ACID transactions handle atomic updates across tables effortlessly. In a sharded architecture, those guarantees vanish once a write touches more than one shard. You need patterns that maintain correctness without freezing the system under distributed locks.
4.2.1 Two-Phase Commit (2PC): Limitations and Performance Penalties
Two-phase commit sounds like the natural solution: ask every shard if it’s ready, then commit all at once. But in practice, it becomes a bottleneck. Every participant must hold locks while waiting for a decision, and a coordinator failure can leave shards stuck in uncertain states.
In .NET, 2PC usually means relying on DTC or XA-like behavior in the database engine. Both approaches add latency, reduce throughput, and create operational complexity. When hundreds or thousands of transactions per second are flowing through the system, 2PC quickly becomes a limiting factor.
For these reasons, most sharded systems avoid 2PC entirely, except for low-frequency administrative operations where performance doesn’t matter.
4.2.2 The Saga Pattern: Implementing Choreography/Orchestration Using MassTransit or NServiceBus
Sagas are the practical alternative to cross-shard transactions. They break a large operation into smaller, independent steps. Each step updates data locally in its own shard. If something goes wrong, the system runs compensating actions to undo or adjust previous steps.
With MassTransit or NServiceBus, sagas become easier to orchestrate in .NET. Each shard performs only the work relevant to its data. A central saga state keeps track of the process and publishes events to move the workflow forward.
public class OrderState : SagaStateMachineInstance
{
public Guid CorrelationId { get; set; }
public string CurrentState { get; set; }
public long OrderId { get; set; }
}
public class OrderSaga : MassTransitStateMachine<OrderState>
{
public State InventoryReserved { get; private set; }
public Event<OrderCreated> OrderCreated { get; private set; }
public Event<InventoryReservedEvent> InventoryReservedEvent { get; private set; }
public OrderSaga()
{
InstanceState(x => x.CurrentState);
Initially(
When(OrderCreated)
.Then(context => context.Instance.OrderId = context.Data.OrderId)
.Publish(context => new ReserveInventory(context.Instance.OrderId))
.TransitionTo(InventoryReserved));
During(InventoryReserved,
When(InventoryReservedEvent)
.Publish(context => new ProcessPayment(context.Instance.OrderId))
.Finalize());
}
}Instead of locking multiple shards, each shard processes its own step. If payment fails, for instance, inventory can be released through a compensation event. This fits sharded environments naturally.
4.2.3 Achieving Eventual Consistency with Outbox Patterns
The outbox pattern ensures messages and data changes stay consistent without involving distributed transactions. A service writes its data and its outgoing messages in the same local transaction. A background processor then reads the outbox table and publishes the messages.
public class OutboxMessage
{
public Guid Id { get; set; }
public string Payload { get; set; }
public DateTime CreatedUtc { get; set; }
}
public async Task SaveOrderAsync(Order order)
{
var outbox = new OutboxMessage
{
Id = Guid.NewGuid(),
Payload = JsonSerializer.Serialize(new OrderCreated(order.Id)),
CreatedUtc = DateTime.UtcNow
};
_db.Orders.Add(order);
_db.Outbox.Add(outbox);
await _db.SaveChangesAsync();
}A hosted worker moves messages out of the outbox:
public class OutboxProcessor : BackgroundService
{
private readonly IDbContextFactory<AppDbContext> _factory;
public OutboxProcessor(IDbContextFactory<AppDbContext> factory)
{
_factory = factory;
}
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
while (!stoppingToken.IsCancellationRequested)
{
using var db = _factory.CreateDbContext();
var msgs = await db.Outbox.OrderBy(x => x.CreatedUtc)
.Take(100)
.ToListAsync(stoppingToken);
foreach (var msg in msgs)
{
await PublishMessage(msg);
db.Outbox.Remove(msg);
}
await db.SaveChangesAsync(stoppingToken);
await Task.Delay(500, stoppingToken);
}
}
}This approach gives you reliable, eventually consistent messaging across shards without forcing global locks or distributed transactions. It’s one of the most widely used techniques for real-world sharded systems.
5 Technology-Specific Implementations: The “Big Three”
Each database engine approaches sharding differently. Some provide built-in routing and coordination; others rely on the application to manage shard selection. In .NET, your routing layer stays the same, but the database-specific details vary. This section walks through SQL Server, PostgreSQL, and MongoDB—three engines commonly used in enterprise .NET applications—and explains how sharding fits into each ecosystem.
5.1 SQL Server
SQL Server doesn’t include native distributed sharding the way MongoDB or Citus do. Instead, Microsoft provides tools that help you implement application-driven sharding in a structured and manageable way. When paired with your .NET routing layer, you can create a reliable horizontal scaling setup.
5.1.1 Utilizing Azure Elastic Database Client Library
Azure Elastic Database tools give SQL Server a sharding “control plane.” Instead of managing shard mappings manually, you store tenant-to-database relationships in a Shard Map. The Elastic Database Client Library then uses that map to route connections and handle caching, retries, and failover details.
A typical shard lookup looks like this:
var credentials = new SqlCredential("user", password);
var shardMapManager = ShardMapManagerFactory.GetSqlShardMapManager(
shardMapManagerConnectionString,
ShardMapManagerLoadPolicy.Lazy);
var shardMap = shardMapManager.GetListShardMap<int>("TenantShardMap");
using var conn = shardMap.OpenConnectionForKey(tenantId, baseConnectionString);This connects cleanly with the sharding middleware described earlier. The shard map essentially acts like a directory-based sharding model—your .NET routing layer retrieves shard information from the map rather than calculating it through hashing or ranges.
Azure also supports automated split-merge operations for rebalancing tenants. This helps avoid writing custom migration scripts every time a shard grows too large.
5.1.2 Managing Schema Drift Across Shards Using DacPacs
Once your system has many SQL Server shards, schema consistency becomes a real operational challenge. DacPacs solve this by packaging your schema into a repeatable unit that you can deploy everywhere.
A simple deployment loop might look like this:
$shards = Get-Content "./shard-list.txt"
foreach ($shard in $shards) {
sqlpackage /Action:Publish `
/SourceFile:./AppSchema.dacpac `
/TargetConnectionString:$shard `
/p:BlockOnPossibleDataLoss=false
}This ensures every shard stays aligned with the same schema version. Most teams automate this in CI/CD pipelines, adding checks to ensure no shard falls behind. Schema drift across dozens of databases quickly leads to subtle runtime bugs, so DacPacs play an important stabilization role in SQL-based sharding environments.
5.2 PostgreSQL
PostgreSQL has excellent partitioning features, but true distributed sharding requires additional tooling. Depending on the scale and workload, teams either use application-side routing (like SQL Server) or adopt Citus, which turns PostgreSQL into a distributed cluster.
5.2.1 Native Declarative Partitioning vs. Application-Side Sharding
Declarative partitioning divides data inside a single PostgreSQL instance. This works well for large tables, but everything still shares the same CPU, memory, and storage. Once your dataset exceeds what one machine can reasonably support, application-level sharding becomes necessary.
A typical partitioned table looks like:
CREATE TABLE orders (
id bigint primary key,
created_at timestamptz not null,
tenant_id int not null
) PARTITION BY RANGE (created_at);This structure gives the optimizer more freedom, reduces bloat, and speeds up certain queries. But it does not provide true horizontal scale. The .NET routing layer must still decide which database to connect to when sharding across multiple PostgreSQL instances.
5.2.2 Citus Data: Converting PostgreSQL into a Distributed Database (Coordinator/Worker Architecture)
Citus turns PostgreSQL into a distributed cluster by adding a coordinator node and multiple worker nodes. The coordinator accepts queries and routes them based on a distribution key—essentially acting as a database-side router.
To distribute a table:
SELECT create_distributed_table('orders', 'tenant_id');From a .NET perspective, using Citus feels the same as using a normal PostgreSQL instance:
var builder = new NpgsqlConnectionStringBuilder
{
Host = "citus-coordinator",
Username = "app",
Password = "pwd",
Database = "appdb"
};
using var conn = new NpgsqlConnection(builder.ConnectionString);Because the coordinator sits between the application and the workers, Citus manages shard placement, rebalancing, and distributed query execution. This offloads a significant amount of responsibility from your .NET routing layer. However, cross-shard joins still have a cost, so picking the right shard key remains critical.
5.3 MongoDB
MongoDB stands out because sharding is built directly into the database engine. Unlike SQL Server or basic PostgreSQL setups, you don’t have to manage routing logic in .NET unless you want custom behavior. The database takes care of distributing data, routing queries, and balancing chunks.
5.3.1 Config Servers and Mongos (Router) Architecture
A MongoDB sharded cluster includes three types of components:
- Config servers store metadata, including shard ranges and chunk placement.
- Shard servers (replica sets) hold the actual data.
- Mongos routers accept application queries and route them to the correct shard.
Your .NET application connects to mongos instead of connecting directly to shard servers. Mongos handles all routing decisions, which means you don’t need application-side hashing or lookup logic unless you want additional control.
5.3.2 Choosing a Shard Key (Cardinality and Frequency)
In MongoDB, choosing the right shard key is one of the most important decisions you make. The key should have:
- High cardinality so data spreads evenly
- Even access patterns so query load doesn’t bunch up
- Predictable write distribution to avoid hot chunks
For multi-tenant workloads, compound keys often work best:
sh.shardCollection("app.orders", { tenantId: 1, orderId: 1 });This places tenants across shards while keeping orders for a single tenant grouped together. Time-series keys—or any monotonically increasing key—tend to overload the newest chunk, so MongoDB users often avoid simple timestamp sharding unless paired with additional entropy.
5.3.3 C# Driver Configuration for Sharded Clusters
The MongoDB C# driver works naturally with mongos routers. Sharding-specific settings usually relate to consistency and write acknowledgment rather than connection behavior.
var settings = MongoClientSettings.FromConnectionString(
"mongodb://router1,router2/?replicaSet=rs0&readPreference=primary");
settings.WriteConcern = WriteConcern.WMajority;
var client = new MongoClient(settings);
var db = client.GetDatabase("app");Globally unique IDs like Snowflake or UUID v7 work particularly well with MongoDB’s _id index because their sortable nature distributes inserts more evenly across shards. This reduces chunk hotspotting and leads to smoother autosplitting behavior.
6 Cross-Shard Querying and Reporting Aggregation
After sharding, writes usually become faster and more predictable because each shard handles only a portion of the load. The challenge shifts to reads—especially queries that need data from multiple shards. Operational queries can often stay shard-local, but reporting, dashboards, and analytics rarely have that luxury. This section explains practical patterns for retrieving data across shards while keeping latency manageable and avoiding unnecessary strain on the system.
6.1 The Scatter-Gather Pattern: Parallelizing Queries in .NET Using Task.WhenAll
Scatter-gather is the simplest and most direct way to query multiple shards. Instead of running the same query on each shard sequentially—which becomes painfully slow as shard counts grow—you run all of them in parallel and merge the results. This works regardless of the database engine because the routing layer simply provides the list of shard connection strings.
A typical .NET implementation collects all shard tasks and waits for them:
public async Task<IReadOnlyList<OrderSummary>> QueryAllShardsAsync(string sql)
{
var tasks = new List<Task<IEnumerable<OrderSummary>>>();
foreach (var shard in _shardRegistry.AllShards)
{
tasks.Add(QueryShard(shard, sql));
}
var results = await Task.WhenAll(tasks);
return results.SelectMany(r => r).ToList();
}
private async Task<IEnumerable<OrderSummary>> QueryShard(string conn, string sql)
{
await using var c = new SqlConnection(conn);
await c.OpenAsync();
var cmd = new SqlCommand(sql, c);
var reader = await cmd.ExecuteReaderAsync();
var list = new List<OrderSummary>();
while (await reader.ReadAsync())
{
list.Add(new OrderSummary
{
OrderId = reader.GetInt64(0),
Total = reader.GetDecimal(1)
});
}
return list;
}In real systems, you rarely fire unlimited parallel queries. Large clusters can overload themselves if you hit every shard at once. Most teams add a small semaphore or channel to limit concurrency—say, running five shards at a time. Latency-sensitive systems also track slow shards and return partial data rather than waiting for stragglers.
Scatter-gather works well for summary-style queries, exporting data, or searching by known keys. It becomes difficult when queries involve heavy joins or unbounded scans. When those types of queries become common, you often outgrow scatter-gather and start thinking about dedicated read models.
6.2 Handling Pagination: The Challenges of SKIP/TAKE Across Distributed Datasets
Pagination is one of the first things that gets complicated after sharding. In a monolithic database, ORDER BY created_at LIMIT 50 OFFSET 100 works fine. In a sharded world, each shard returns its own slice of data, and there’s no natural way to combine them into one properly ordered list without doing extra work.
A naive approach—applying the same SKIP/TAKE on every shard—fails because it ignores global ordering. One shard might return rows that belong earlier or later in the global sequence. The correct solution is to use cursor-based pagination, where each shard filters results using a key greater than the last retrieved value.
A per-shard query might look like:
SELECT id, total, created_at
FROM orders
WHERE created_at > @cursor
ORDER BY created_at
LIMIT 50;Then the .NET application merges the results with something similar to a merge sort:
public List<Order> MergeSorted(List<List<Order>> shardResults, int pageSize)
{
var pq = new PriorityQueue<Order, DateTime>();
foreach (var shard in shardResults)
{
foreach (var row in shard)
pq.Enqueue(row, row.CreatedAt);
}
var output = new List<Order>();
while (output.Count < pageSize && pq.TryDequeue(out var item, out _))
output.Add(item);
return output;
}Key points:
- Cursor-based pagination avoids expensive large offsets.
- Each shard can index the sort key (Snowflake ID, timestamp, etc.).
- The application tracks one cursor per shard for the next page.
Teams moving from a monolith usually replace offset-based pagination with cursor-based pagination before sharding because it simplifies downstream logic dramatically.
6.3 CQRS (Command Query Responsibility Segregation)
Even with scatter-gather and cursor-based pagination, cross-shard queries eventually hit limits. When reporting workloads grow or queries become more complex, a separate read model becomes easier to maintain. CQRS lets sharded databases focus on writes while a consolidated read model handles the heavy analytics.
In a CQRS setup:
- Write side: data is sharded and optimized for transactional throughput.
- Read side: data is aggregated and denormalized into a single store.
The read model is populated using events or change data capture, and it doesn’t need to be strongly consistent. A delay of a few seconds or minutes is often acceptable for analytics.
6.3.1 Offloading Complex Reads to a Consolidated Read Model (Data Lake/Warehouse)
A consolidated read model can live in a variety of places: another SQL database, a data warehouse, a data lake, or a columnar engine. The point is that queries go to one place, not every shard.
Here’s what a basic ingestion handler looks like using a message-driven approach:
public class OrderIngestionHandler : IConsumer<OrderCreated>
{
private readonly ReportingDbContext _reportDb;
public OrderIngestionHandler(ReportingDbContext reportDb)
{
_reportDb = reportDb;
}
public async Task Consume(ConsumeContext<OrderCreated> context)
{
var evt = context.Message;
_reportDb.OrderSummaries.Add(new OrderSummaryRead
{
OrderId = evt.OrderId,
TenantId = evt.TenantId,
Total = evt.Total,
CreatedAt = evt.CreatedAt
});
await _reportDb.SaveChangesAsync();
}
}The read model usually contains:
- flattened or denormalized tables
- precomputed rollups
- specialized indexes for fast dashboards
Because the read model doesn’t handle writes from the application directly, query engineers can optimize freely without affecting transaction throughput.
6.3.2 Using ElasticSearch or Specialized Analytics DBs as the Aggregation Layer
When analytics become more advanced, storing the read model in ElasticSearch or a columnar database often provides better performance. ElasticSearch handles text search, aggregations, and distributed indexing natively. It also scales horizontally, which aligns well with a sharded write model.
A simple indexing batch might look like:
public async Task IndexOrdersAsync(IEnumerable<OrderSummaryRead> batch)
{
var bulk = new BulkDescriptor();
foreach (var order in batch)
{
bulk.Index<OrderDocument>(i => i
.Index("orders")
.Id(order.OrderId)
.Document(new OrderDocument
{
OrderId = order.OrderId,
TenantId = order.TenantId,
Total = order.Total
}));
}
await _elasticClient.BulkAsync(bulk);
}Columnar databases such as ClickHouse, Snowflake, or Azure Synapse also work well for large-scale analytics. They excel at aggregations across huge datasets and remove the need for scatter-gather entirely. Your .NET code simply queries the analytics store directly.
7 Operations: Rebalancing, Resharding, and Monitoring
Sharding solves scaling problems, but it also creates new operational responsibilities. Data grows unevenly, tenants expand at different rates, and hardware or regional requirements change over time. A healthy sharded system needs routine maintenance—rebalancing, monitoring, and controlled migrations. Most issues don’t appear as outages; instead, they show up as skew, latency variance, or unexpected load on a single shard. This section focuses on how to keep the system stable as it evolves.
7.1 Shard Rebalancing Strategies
Rebalancing distributes data more evenly across shards when one shard grows faster than others. How you move data depends on which sharding strategy you use—hash-based, range-based, or directory-based. Hashing systems usually rely on virtual buckets, while directory-based systems move specific tenants between shards.
7.1.1 Moving “Virtual Buckets” Rather Than Individual Rows
Virtual buckets make rebalancing practical. Instead of trying to move millions of rows directly from one shard to another, the system groups keys into bucket-sized units. A bucket might represent a range of hashed keys or a slice of the shard key space. When a shard becomes overloaded, you move one or more buckets to a new shard.
A migration workflow typically follows this pattern:
public async Task MoveBucketAsync(int bucketId, string targetShard)
{
var sourceShard = _map.GetShard(bucketId);
var data = await _copier.CopyBucketAsync(sourceShard, bucketId);
await _copier.WriteBucketAsync(targetShard, bucketId, data);
_map.UpdateShard(bucketId, targetShard);
}From the application’s perspective, the move appears atomic—one moment the bucket lives on shard A, and the next moment it’s on shard B. Consistent hashing systems naturally align buckets with segments of the ring, so adding or removing nodes only shifts the ranges that belong to those segments. This keeps rebalancing predictable and reduces the amount of data that moves during scale-out.
7.1.2 Handling “Jumbo Chunks” (Data That Cannot Be Split)
Some keys grow too large or too active to fit neatly inside a bucket. These “jumbo chunks” show up in systems with uneven tenant sizes or workloads where a single customer generates disproportionate traffic. They create hotspots that no amount of hashing can smooth out.
When this happens, teams usually take one of these approaches:
- Dedicated shard: Assign the large tenant to its own shard.
- Sub-sharding: Split the tenant’s data using secondary keys.
- Routing rules: Add custom logic so related data gets distributed over multiple buckets.
During migrations, it’s common to throttle reads and writes for the affected tenant so the data copy doesn’t overwhelm either shard. Platforms that track bucket sizes over time can catch jumbo chunks early, before they start affecting performance.
7.2 Observability
With sharding, the database layer becomes distributed, which means failures become subtle. Instead of the whole system going down, a single shard might slow down, or routing might send requests to the wrong node. Proper observability helps you detect these issues early.
7.2.1 Distributed Tracing with OpenTelemetry
OpenTelemetry is essential for understanding how requests move across shards. Instead of tracing requests inside a single database, you now trace spans across multiple databases. Each database call becomes its own span, and the entire request becomes a trace. That makes it easy to identify slow shards or unexpected routing behavior.
Example instrumentation:
var activitySource = new ActivitySource("ShardRouting");
public async Task<T> ExecuteOnShardAsync<T>(string shardId, Func<DbConnection, Task<T>> exec)
{
using var activity = activitySource.StartActivity("QueryShard");
activity?.SetTag("shard.id", shardId);
await using var conn = _factory.Create(shardId);
await conn.OpenAsync();
return await exec(conn);
}With Jaeger, Zipkin, or OTLP exporters, an engineer can instantly see differences in query times across shards. This helps detect skew, routing mistakes, or intermittent performance regressions long before they become outages.
7.2.2 Monitoring “Data Skew” and “Hot Spots”
Data skew happens when one shard carries too much load or data volume compared to the others. This is one of the most common issues in long-running sharded systems. The symptoms usually appear first as slow queries or increased CPU usage on a single shard.
Metrics to track include:
- Requests per shard
- Average query latency per shard
- Storage size and index growth
- Tenant activity distribution
- Error rates and throttling patterns
Once you see skew increasing, you can plan a rebalance before it becomes a user-visible problem. Many teams automate alerts when a shard exceeds a certain percentage of total data or throughput.
7.3 Schema Migrations
Schema changes become more complicated when you have many databases instead of one. A migration that takes a few seconds on a monolith might take several minutes—or hours—when applied to dozens or hundreds of shards. The system must stay live during the process, so your migrations need to be backward compatible.
7.3.1 Rolling Updates Across Shards (Avoiding Global Locks)
Rolling migrations update shards one at a time instead of applying the change everywhere simultaneously. This keeps the system available and avoids putting multiple shards under schema locks at once.
A safe migration plan usually looks like this:
- Additive change: Introduce new columns or tables in a non-breaking way.
- Deploy application update: Start writing to both the old and new structures.
- Backfill: Copy or transform data in the background.
- Clean up: Remove old fields and columns in a later release.
Because each shard may be updated at a slightly different time, the application must handle both versions of the schema temporarily. This approach keeps workloads running smoothly even during large rollouts.
7.3.2 Tools: DbUp vs. EF Core Migrations in a Multi-DB Context
DbUp is a lightweight tool for applying SQL scripts, and it works well when you need fine-grained control across many shards. It runs scripts in a defined order, tracks execution per database, and avoids tying schema evolution directly to EF Core’s model snapshots.
EF Core migrations still work for sharded systems, but you usually need a custom runner that loops through each shard connection. EF migrations assume a consistent schema across databases, so rolling deployments must be backward compatible.
Example DbUp runner:
foreach (var shard in shardConnections)
{
var upgrader =
DeployChanges.To
.SqlDatabase(shard)
.WithScriptsFromFileSystem("Scripts")
.Build();
var result = upgrader.PerformUpgrade();
if (!result.Successful)
throw result.Error;
}Large platforms often combine the two: EF Core defines the schema, while DbUp orchestrates deployment across shards. This hybrid approach gives you strong modeling tools without sacrificing operational control.
8 The Migration Playbook: Monolith to Sharded (Zero Downtime)
Migrating a live system to a sharded architecture is one of the most delicate steps in scaling. You’re changing not just where data lives, but also how the application reasons about identity, routing, and consistency. A successful migration avoids downtime, maintains correctness, and gives teams confidence before traffic fully moves to the new architecture. The approach below reflects how large SaaS platforms and high-throughput consumer systems transition safely.
8.1 Phase 1: Logical Separation – Refactoring the .NET Monolith to Respect Boundaries (Removing Joins)
Sharding only works if the application itself no longer assumes that all data lives in one place. The first step is identifying the future shard boundaries—usually tenant, customer, account, or region—and removing any database operations that cross those boundaries. This avoids multi-shard joins before they exist.
Teams start by reviewing repository and query code and isolating data access to well-defined areas. Cross-table joins that used to be easy inside a monolith must now be replaced by:
- service calls into other domains
- cached lookups
- lightweight denormalized summaries
This process also introduces global IDs (Snowflake, UUID v7, etc.) so records can exist independently of the original database. These IDs become the backbone of routing later.
By the end of this phase, the application’s data access patterns no longer assume global visibility. Everything is structured so routing can be introduced without rewriting core business logic.
8.2 Phase 2: Dual Write / Backfill
Once the application can operate without cross-database joins, you can begin writing data to both the monolith and the new sharded layout. The monolith remains the source of truth; shards slowly fill up with a consistent copy of the same records. This is the longest phase because the goal is to build trust in the sharded version without affecting production traffic.
8.2.1 Writing to Both Monolith and Shards Simultaneously
Dual write requires stable routing logic, meaning the application knows how to compute the correct shard based on tenant, user, or entity ID. Every write sends data to both locations, but only the monolith is used for reads.
A common .NET pattern wraps shard writes with resilience and telemetry so failures don’t impact primary behavior:
public async Task CreateOrderAsync(Order order)
{
// Always write to monolith first
await _monolithRepo.InsertAsync(order);
try
{
// Then write to the appropriate shard
await _shardedRepo.InsertAsync(order);
}
catch (Exception ex)
{
_logger.LogError(ex, "Shard write failed");
// Shard is secondary, so monolith continues normally
}
}This allows teams to test routing behavior, monitor shard performance, and validate identity generation without affecting customers.
8.2.2 Using Change Data Capture (CDC) (e.g., Debezium) for Data Synchronization
CDC dramatically simplifies backfill and ongoing synchronization. Instead of writing ad hoc copy jobs, the system streams mutations directly from the monolith to the appropriate shard. Debezium, SQL Server CDC, or PostgreSQL logical replication publish row changes to a message broker such as Kafka.
Sharded consumers then apply the changes according to routing rules:
public async Task HandleCdcEventAsync(OrderCdcEvent evt)
{
var shardId = _resolver.Resolve(evt.OrderId);
using var conn = _factory.CreateConnection(shardId);
await _writer.ApplyChangeAsync(conn, evt);
}Historical backfill is performed first using bulk copy tools. Once CDC catches up, shard data is nearly identical to the monolith, and drift becomes easy to track.
8.3 Phase 3: Dark Reads – Comparing Monolith Reads vs. Shard Reads for Accuracy
Dark reads validate that the sharded data is accurate without exposing inconsistencies to users. The application continues returning monolith results but quietly compares them to sharded results in the background. This identifies routing bugs, CDC gaps, or schema issues long before cutover.
The pattern is simple:
public async Task<Order> GetOrderAsync(long id)
{
var mono = await _monolithRepo.GetAsync(id);
_ = Task.Run(async () =>
{
var shard = await _shardedRepo.GetAsync(id);
if (!OrderComparer.AreEqual(mono, shard))
_logger.LogWarning("Mismatch for order {Id}", id);
});
return mono;
}Teams typically track mismatch rates over time and drill into the causes. Most discrepancies come from incorrect handling of updates, missing CDC messages, or unexpected edge cases in the shard key logic. You stay in this phase until mismatch rates fall close to zero.
8.4 Phase 4: The Cutover – Switching the “Source of Truth” Toggle
Cutover begins only after dual writes are reliable and dark reads show consistent results. This phase shifts real production reads from the monolith to the sharded system. Writes are still dual until the team is confident that the shard layout works under real load.
The switch usually happens behind a feature flag:
if (_featureFlags.ShardReadsEnabled)
return await _shardedRepo.GetAsync(id);
return await _monolithRepo.GetAsync(id);Teams monitor:
- shard latency
- mismatches
- shard failovers
- routing accuracy
- key distribution and load balance
If anything looks wrong, the flag rolls back instantly, and the monolith resumes full responsibility. Once the system proves stable, monolith writes are disabled, and the sharded system becomes the new source of truth. The monolith typically moves into read-only archival mode or is retired entirely.